Introduction
In this tutorial, we will be looking into how you can do various kinds of interesting reporting using Google's BigQuery bitcoin blockchain data. This can be used to run various reports including but not limited to finding answers to the following questions.
- How many bitcoins are sent each day?
- How many addresses receive bitcoin each day?
- Compare transaction volume to historical prices by joining with other available data sources
Background
The bitcoin core client software currently stores various bits of data as on disk which has been optimised for the running and execution when hosting a bitcoin node. The structure in which this is data is stored however is in a normalised form and optimised for the running of the node, not for reporting purposes.
Although there are many ways in which we can extract and report on this data, this tutorial we will be looking into Google's denormalised data set which is frequently updated and has been optimised for reporting.
For this tutorial, having some experience with python and SQL might be advantageous, but are not required for following along.
Let's get started!
Update:
Shortly after writing this tutorial, Google appear to have collated a list of blockchain data sets under their Blockchain ETL (Extract, Transform and Load) initiative, and therefore it seems they have deprecated the older data set calledbigquery-public-data.bitcoin_blockchainin favour ofbigquery-public-data.crypto_bitcoin. We have reached out to the relevant parties to provide more clarification on this and will report back as soon as we have more information.
Hi @MeganRisdal! Do you have any clarification on the recent move from
— BitcoinDevNetwork (@BitcoinDevNet) February 11, 2019
bigquery-public-data.bitcoin_blockchain to bigquery-public-data.crypto_bitcoin, if so, when we can expect to see crypto_bitcoin on kaggle? :Dhttps://t.co/3JdE3LYvyg#bitcoin #GoogleBigQuery
Google's old dataset was provided under the name called the bitcoin_blockchain which consisted of two tables, nl blocks and transactions. A more recent version of this is now exposed under the name crypto_bitcoin, has introduced some modification in the schema and the addition of two views for inputs and outputs. We can report on these using standard sql based queries as follows.
SELECT
count(`hash`)
FROM
`bigquery-public-data.crypto_bitcoin.blocks` blocks
When executing the above, we get the following result.
[
{
"f0_": "562509"
}
]
In the above query, we are selecting all the records from the blocks table, then aggregating them using a function called count which returns the number of records available in this record set.
Here we can see that the current block height is recored at 562509. Google suggests that they are updating the information using their ETL processes frequently, so the data in these sets might lag behind the current blockchain data.
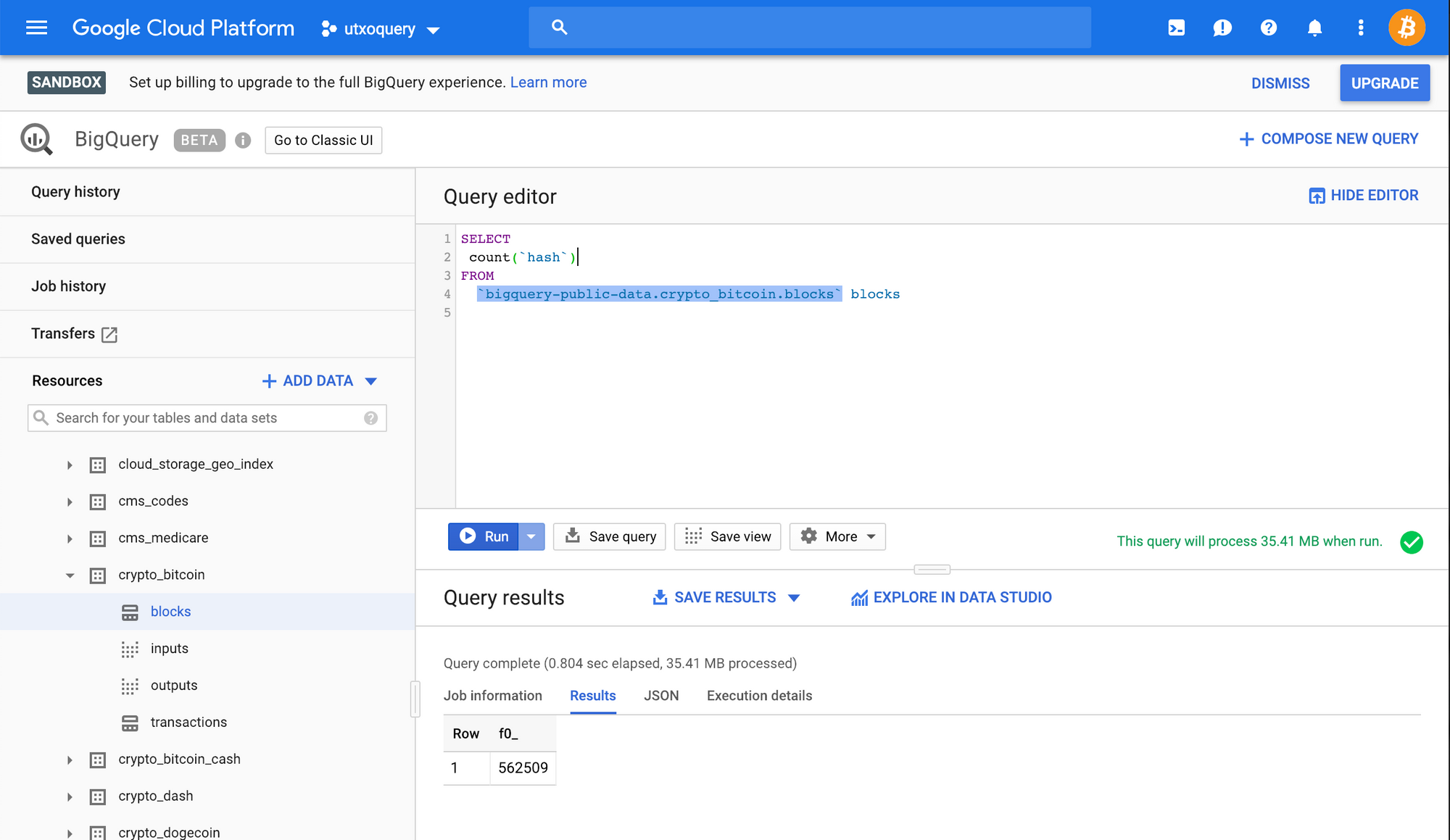
Accessing Google's big query requires a few steps to get started, and is rate limited. In order to overcome getting bogged down by this, we'll be looking at our first example using a site called kaggle, a place to do data science projects.
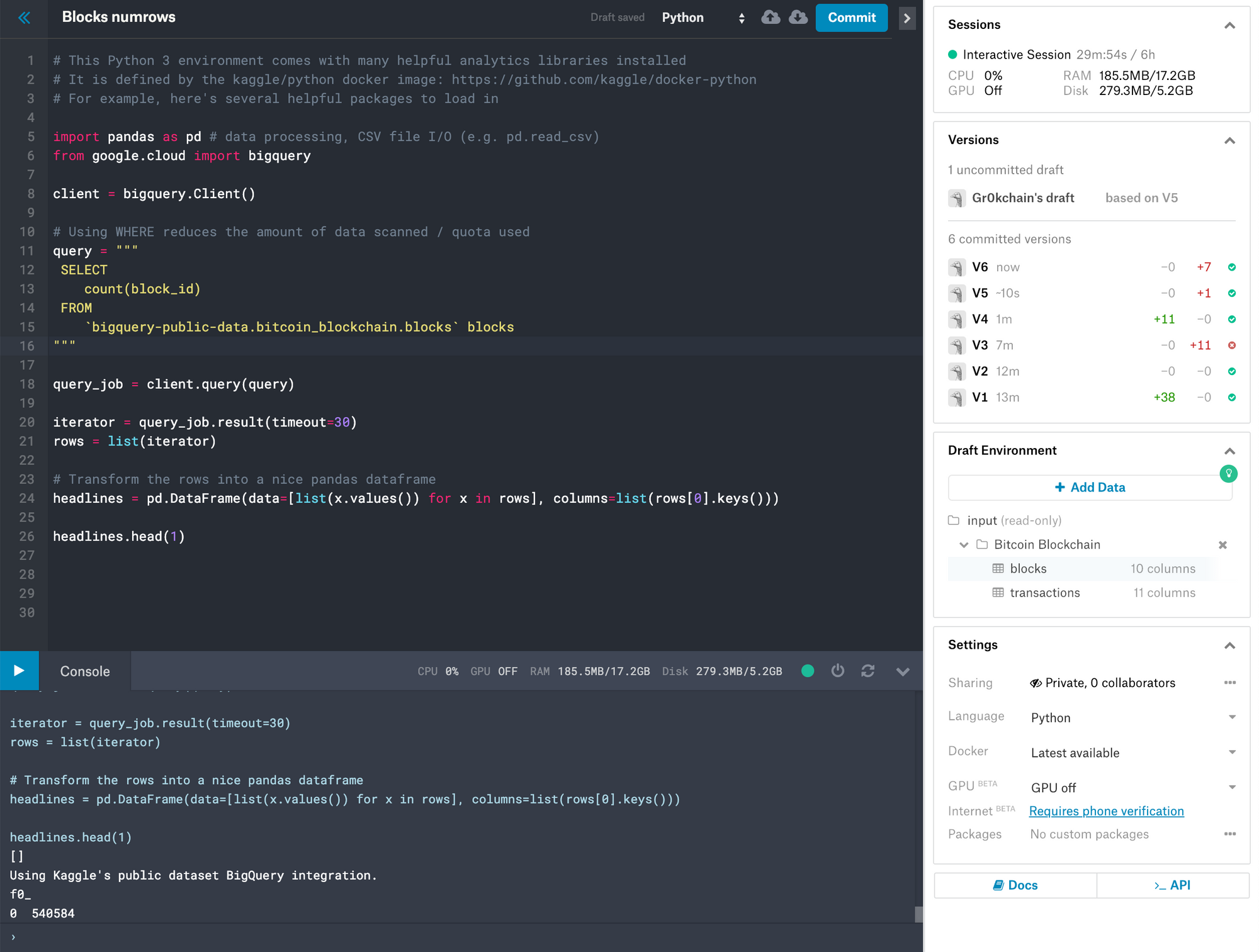
The above kernel is hosted on kaggle at https://www.kaggle.com/bitcoindevnet/blocks-numrows
Kaggle allows us to write programs in both python and R for the purpose of reporting on datasets, including google's BigQuery Bitcoin Blockchain database.
Our kaggle example can be broken down as follows.
First we import our Python Data Analysis Library (pandas) and google.cloud from the bigquery library.
from google.cloud import bigquery
Next, we create a new instance of the bigquery client.
client = bigquery.Client()
We then assign our query to a variable called query.
# Using WHERE reduces the amount of data scanned / quota used
query = """
SELECT
count(block_id)
FROM
`bigquery-public-data.bitcoin_blockchain.blocks` blocks
"""
Note
The above data set is being exposed under what appears to be an unmaintained version of the data usingbigquery-public-data.bitcoin_blockchain. This has now been moved tobigquery-public-data.crypto_bitcoinwhich uses a slightly different schema.
Here we execute our query using the query method of our client instance and assign it to a variable called query_job.
query_job = client.query(query)
Our query_job variable should contain a record set assuming our query was executed successfully. We then proceed to initialise an iterator by executing the results method from our query_job object. We also obtain a number of records which we assign to our rows variable.
iterator = query_job.result(timeout=30)
rows = list(iterator)
We iterate though our result set and assign this to a pandas DataFrame called headlines, together with a list of column names from our record set.
headlines = pd.DataFrame(data=[list(x.values()) for x in rows], columns=list(rows[0].keys()))
Finally, we print the the first frame from our headlines DataFrame.
headlines.head(1)
And that's all there is to it! Using Google's big query for analysing bitcoin blockchain data can be useful. Here is another simple kaggle example for finding out which transaction currently has the most amounts of outputs generated.
SELECT
block_id,
ARRAY_LENGTH(outputs)
FROM
`bigquery-public-data.bitcoin_blockchain.transactions`
ORDER BY ARRAY_LENGTH(outputs) DESC
LIMIT 1
Running this query results in the following.
Using Kaggle's public dataset BigQuery integration.
block_id f0_
0 000000000000000002637cfa48bdc97203a812484ae92d... 13107
https://www.kaggle.com/bitcoindevnet/utxo-count/
Creating your own kaggle
To create your own kaggle, sign up with them, then visit their bitcoin blockchain data dataset and select the New Kernel option at the top right hand side of the page. You can also explore a list of existing kernels and discussions by other users around this data set.
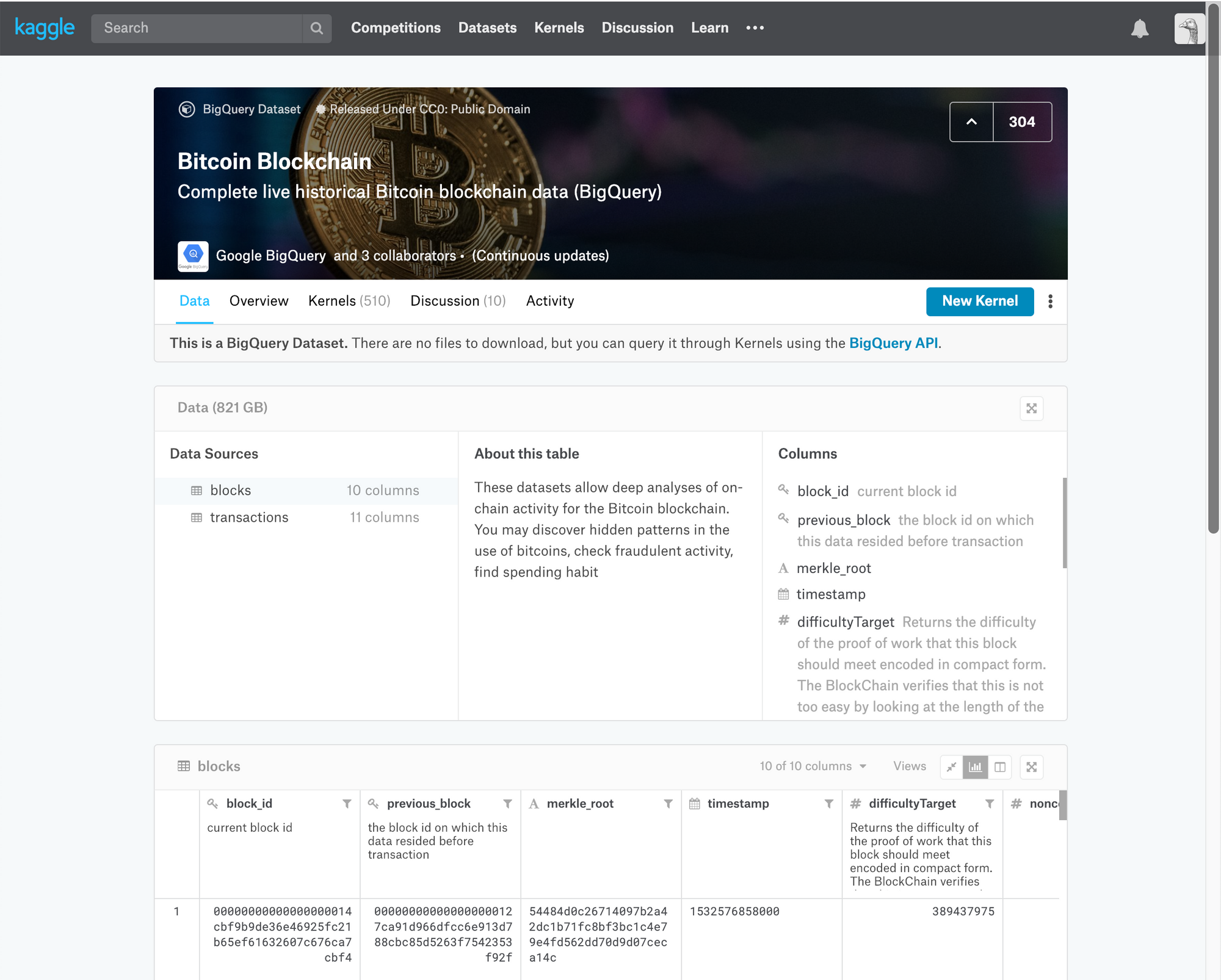
Once selected, you will be presented with two options.
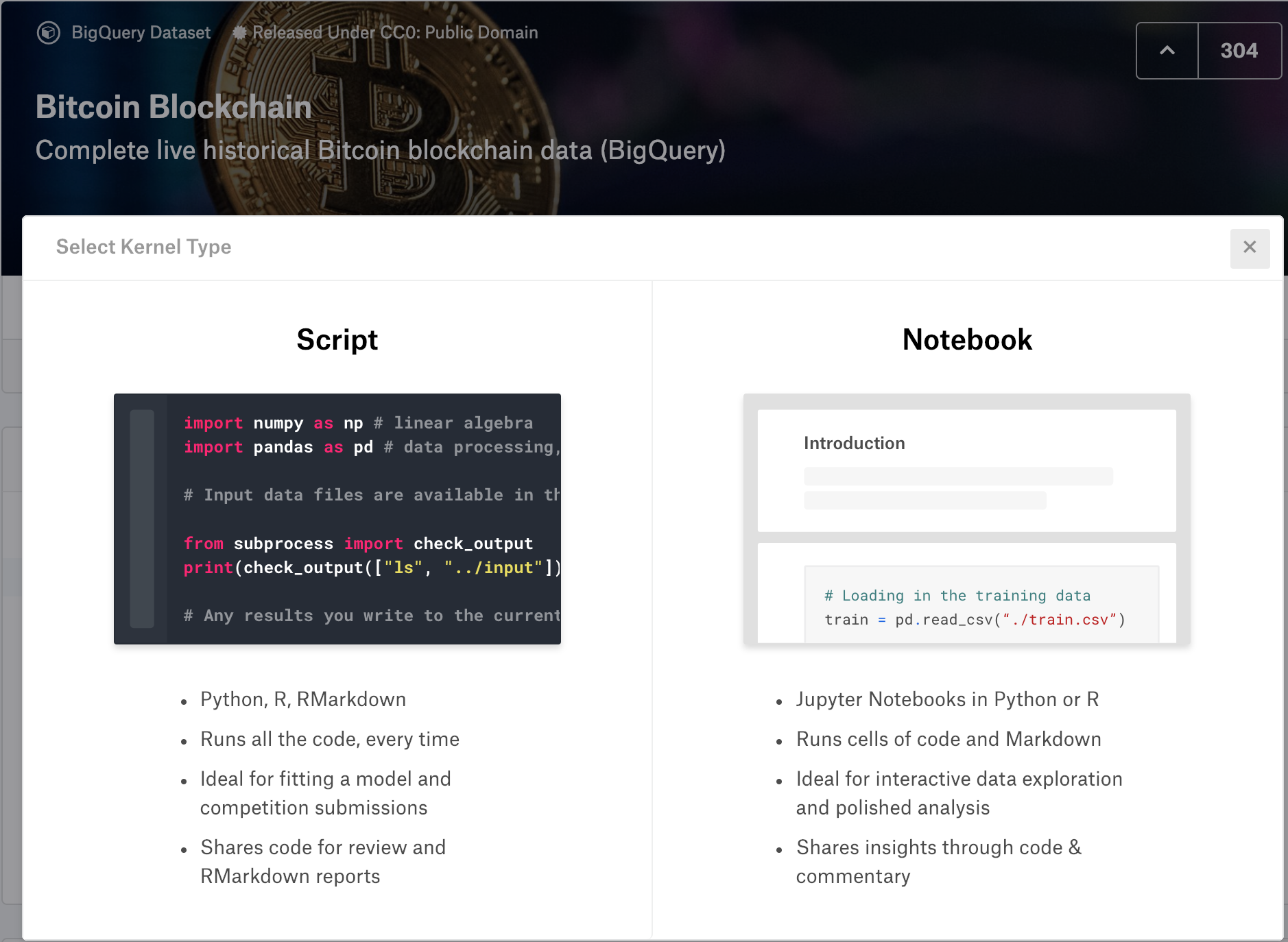
Select your preferred environment, although, novices might prefer using the Notebook interface.
You should now be presented with an interface where you can start hacking together your very own kaggle, and sharing it with the world. Feel free to share your experiences below in the comments.
Conclusion
In this tutorial we covered ways in which you can use Google's Bitcoin BigQuery dataset for various reporting requirements. For more information on this check out Google's introduction of the topic at bitcoin dataset.

Comments